
 基因测序仪业务 SEQ ALL
基因测序仪业务 SEQ ALL











 核心技术
核心技术 热门应用
热门应用 组学研究
组学研究 文档下载
文档下载 已发表文章
已发表文章 用户成功案例
用户成功案例 在线数据集
在线数据集 多功能中心
多功能中心 客户中心
客户中心 在线支持
在线支持 关于智造
关于智造 专题推荐
专题推荐







2023年7月20日,华大智造杨梦团队在Nature子刊Nature Machine Intelligence上在线发表了Self-play reinforcement learning guides protein engineering一文,发布了名为“ EvoPlay”的算法模型。这是继该团队在NMI发表单细胞对比学习自监督Concerto算法后,时隔一年再度发表AI算法相关文章。

EvoPlay由“Evo”、“Play”两个英文单词组合而成,前者意为进化,指蛋白质分子的功能进化;Play指的是博弈类搜索算法。EvoPlay实际上借鉴围棋自博弈的方式搜索海量蛋白质突变空间,并通过结合不同的功能或结构预测模拟器,像自动驾驶一样训练一个智能体完成指定功能增强的蛋白进化。研究者将AlphaFold家族模型和AlphaGo家族模型有机结合,从而以折叠结构为目标高效地设计蛋白质。
值得一提的是,蛋白质的工程化设计和改造是基因测序仪的底层基础,基因测序仪的迭代升级离不开蛋白工程技术的突破。科学家们通过改造各种各样的蛋白质操纵DNA分子、读取酶催化的信号从而识别碱基序列。从华大智造测序仪试剂里用到的聚合酶、荧光素酶等各种工具酶,到更广范围的生物催化剂、生物传感器、治疗类抗体到生物燃料,都离不开对蛋白质的设计和改造。
蛋白质工程发展,
从定向进化到“从头设计”
21世纪初迎来了生物催化发展的第三次突破——体外版本的达尔文进化,定向进化——模仿自然选择的过程,将蛋白质或核酸的设计引向用户定义的目标。其贡献者Frances Arnold因此被授予2018年诺贝尔化学奖。2019年Arnold又引入了机器学习指导的定向进化MLDE (Machine-learning-guided directed evolution)以提高采样效率来加速进化,目前普通MLDE的随机采样效率并不高效,一方面是采样空间巨大,仅4个氨基酸位点就能达到204(160,000)种组合可能性,随机采样方法难以应对。另一方面是采样空间稀疏,在巨大采样空间中有99%以上序列是无效的,其功能值远低于野生型序列或为0。因此,如何高效地采样一直是蛋白质设计领域的重要课题之一。
另外,蛋白质的功能与其结构强相关,2020年发布的AlphaFold2把人们的注意力重新拉回了对蛋白质结构的解析上。AlphaFold2模型的前半部分包含了由MSA(多序列比对)承载的蛋白质的进化信息,此进化信息也越来越多的被证实可以由蛋白质语言预训练模型的输出替代,例如近期Meta发布的ESMFold[2]。接下来,人们获得了对已知蛋白序列的结构进行精准解析的能力后,使得反过来从指定结构来设计合适的蛋白序列成为了可能,即“从头设计”(De Novo Design)。最新的“从头设计”工具包括RFDesign[3],ProteinMPNN[4]等,都是由华盛顿大学的David Baker教授团队所开发。
强化学习在诸多设计和优化领域都有着广泛的应用,无论是视频游戏[5],下棋[6,7],大语言模型多轮对话聊天(ChatGPT的LLM+RLHF),自动驾驶[8]到核聚变控制[9]。此次,华大智造杨梦带领团队开发的EvoPlay算法,把经典的强化学习应用到了蛋白质设计框架中,不仅能够增强传统MLDE的采样效率,并能够结合最新的蛋白质结构解析模型(AlphaFold2)直接设计出带目标结构的氨基酸序列。EvoPlay既能够用于传统定向进化,也能够被纳入“从头设计”的框架中。
EvoPlay 与 AlphaZero

视频1.EvoPlay概念展示。EvoPlay的蛋白质序列设计过程类似于下棋博弈的过程。在视频中,随着每个棋子的落下,都会产生新的棋盘局势,EvoPlay每下一步棋相当于在蛋白质氨基酸序列的某个位置进行一个氨基酸的突变。这些突变的序列将映射到代表蛋白质功能强度(例如发光强度,与特定分子的亲和力等)的崎岖地形上。地形的高低代表了蛋白质功能的强弱。EvoPlay旨在引导蛋白质进行高效的突变,使其功能达到最高峰,就如同在棋盘上取得胜利一样。(视频设计:杨利华、黄睿、李依格)
DeepMind的下棋策略以及强化学习框架是EvoPlay的灵感来源。AlphaGo是DeepMind最重要的AI模型之一。它是一个基于深度学习和强化学习的人工智能围棋程序,2016年,AlphaGo[6]与世界围棋冠军李世石进行五局三胜的对弈,并以4比1的总比分获胜,引起了广泛的关注和震动。这一胜利标志着人工智能首次在高度复杂的游戏中超越人类顶尖选手。
AlphaZero[7]是DeepMind后续进一步发展的AI模型。它不需要任何人类的经验知识,只需要知道游戏规则便能通过自我对弈和强化学习从零开始学习并掌握多种棋类游戏,包括围棋、国际象棋和日本象棋,它以惊人的速度超越了世界上最强大的棋类引擎,并展示了一种通用的自学习方法,能够适应不同的领域和问题。
而EvoPlay模型便是借鉴了这种方法,并将其运用到了蛋白质设计领域当中。作者将蛋白质序列上每一个位点的突变当作是围棋中的每一次落子,将优化的最终序列当作是一局围棋的结束,通过自我对弈和蒙特卡洛树搜索在蛋白质序列空间中不断的搜索和优化序列,同时作者使用一个代理模型来为每一次位点突变进行奖励,最终成功生成了大量的具有特定功能的序列。
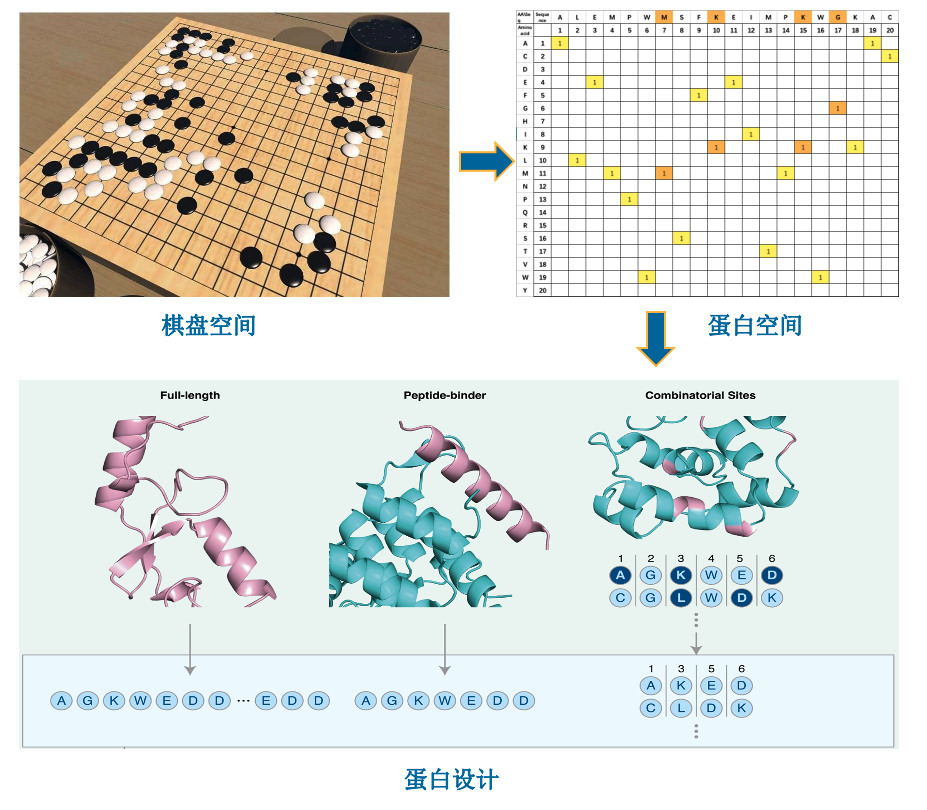
图1. EvoPlay 与 AlphaZero
EvoPlay 与 RLHF
在与人的交流反馈中进行强化学习——RLHF(Reinforcement Learning from Human Feedback),是强化学习领域的一个重要和热门的研究方向。DeepMind, Microsoft Research, Google Brain等机构都在积极投入RLHF的研究。RLHF是一种以人类反馈为训练基础的强化学习策略,也属于基于模型(model based)的强化学习策略。
RLHF是通过在与人互动的过程中获取人类的反馈,训练一个奖励模型(reward model)并据此优化智能体(agent)的策略。目前流行的训练策略(policy)的算法包括ChatGPT使用的近端策略优化(PPO[15] Proximal Policy Optimization),该算法也在EvoPlay基线实验中有应用。与RLHF通过人类反馈训练奖励模型不同,EvoPlay的强化学习模式可以被称为RLPF(Reinforcement Learning from Protein Feedback),即通过蛋白质的反馈训练奖励模型。在EvoPlay的RLPF中,环境奖励同样由一个模型来模拟,这个模型通常被称为代理模型(surrogate)。通过训练蛋白质的功能或者结构相关的数据集得到代理模型,这些数据集和已训练环境模型都包含了蛋白质序列与功能或者结构的对应关系,相当于强化学习的智能体通过改变蛋白质序列与蛋白质进行“交流”,获取功能以及结构反馈信息。
EvoPlay与超大空间蛋白质设计
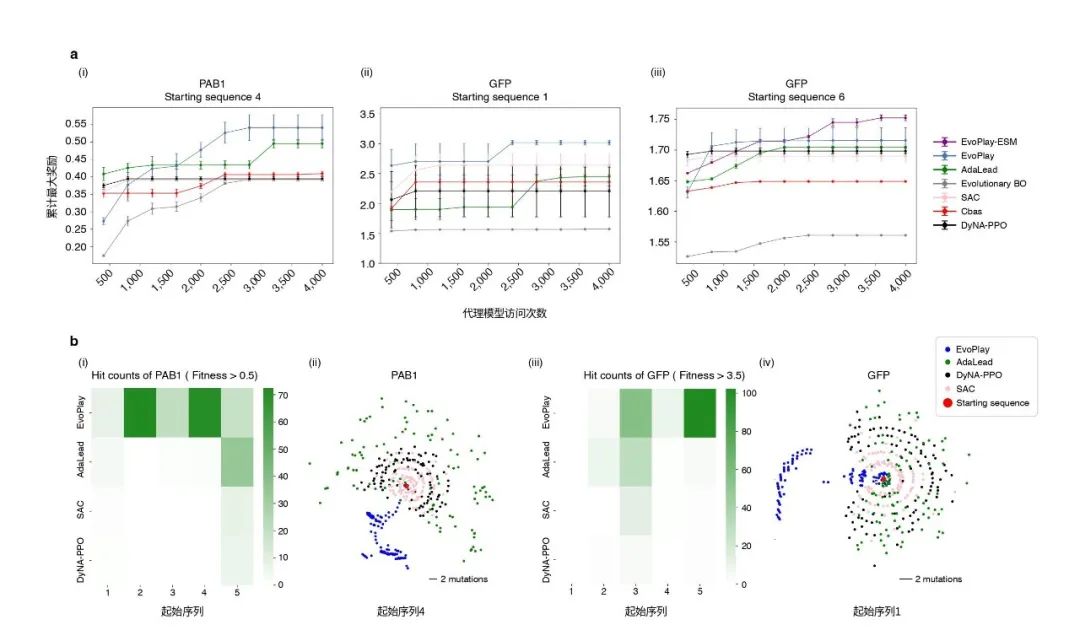
图2. EvoPlay与超大空间蛋白质设计
一张19×19的围棋棋局变数的空间是3361,相当于序列长度为132的蛋白质的设计空间20132, 这个空间远大于宇宙中的粒子数1080。如此庞大的组合空间为蛋白质设计任务带来了巨大的挑战。以本研究的PAB1(Poly(A)-结合蛋白,全长75个氨基酸)和GFP(绿色荧光蛋白,全长237个氨基酸)为例,人们难以为每一个设计的蛋白质序列做实验验证。在强化学习框架下,研究人员需要解决的问题是如何构建模拟环境奖励的代理模型,以及如何在不做或者少做实验的情况下验证该环境奖励的可靠性。
本文的研究人员构造了一个深度卷积神经网络(CNN)来学习这两个数据集已有的部分实验数据,以此模型作为代理模型。另外值得注意的是,本篇文章的研究人员引入了蛋白质语言模型ESM[16,17]来挑选全长位点的子集来缩小设计空间,此方法亦应用于近期发表于Nature Biotechnology的抗体设计中[18]。其原理是蛋白质语言模型在对数以亿级的天然蛋白质进行无监督训练后,能够根据所学到的进化信息输出任意蛋白序列的单个位点的氨基酸分布评估。对于这两个数据集,作者采用了TAPE Transformer[19]作为正交的验证指标器。
验证结果表明,EvoPlay在PAB1和GFP两个数据集上均超越了所有基准对比算法。例如,Adalead[20]在优化过程中频繁进行序列重组,导致其在所有优化高点(local peak)附近“沾边即走”,因此Adalead找到的有效序列比EvoPlay少。贝叶斯优化BO[21]在面对蛋白空间这种高维问题时会面临“维度灾难”问题,导致优化效率降低。基于强化学习的DyNA-PPO[22] 是2020年序列设计领域的最佳模型,但其在优化过程中更换代理模型,导致奖励的不确定性增加,与EvoPlay差距明显。SAC(Soft Actor-Critic)[23]算法旨在最大化奖励和行动的不确定性,虽然经过改进后其效果超过了DyNA-PPO,但其高度的随机性,导致它的性能降低。Cbas[24]是基于隐空间表示的变分自编码器优化,其优化目标不明确。
EvoPlay与AlphaFold2
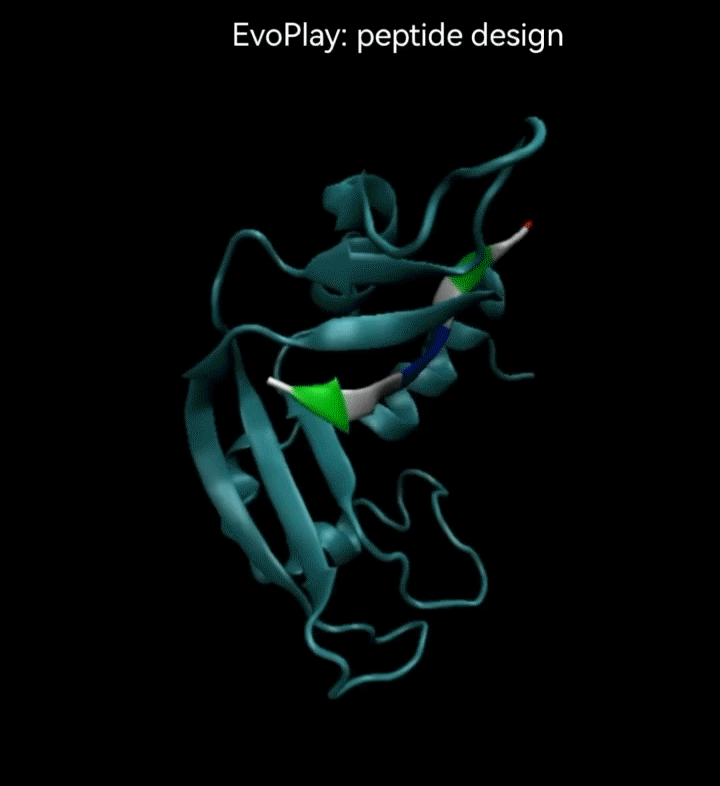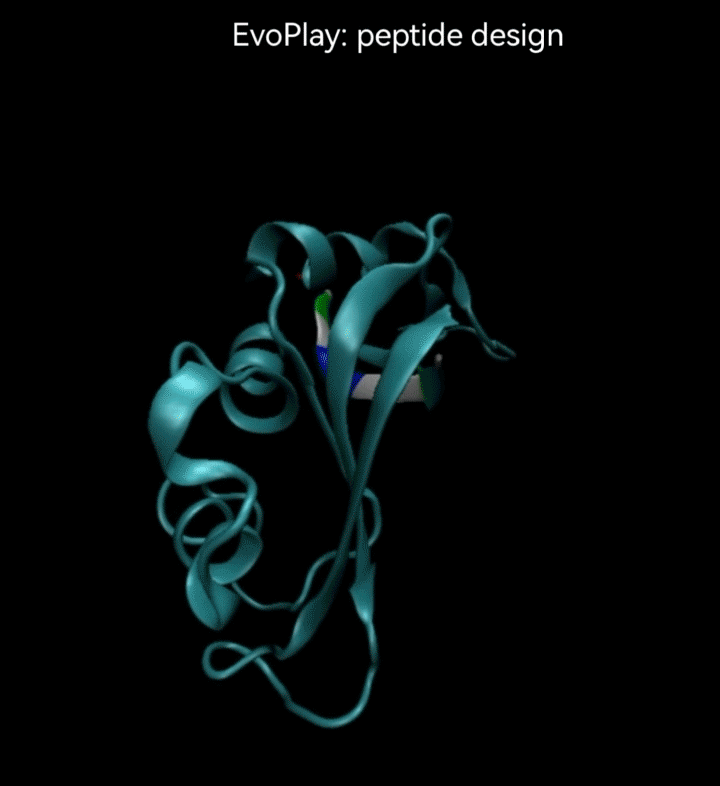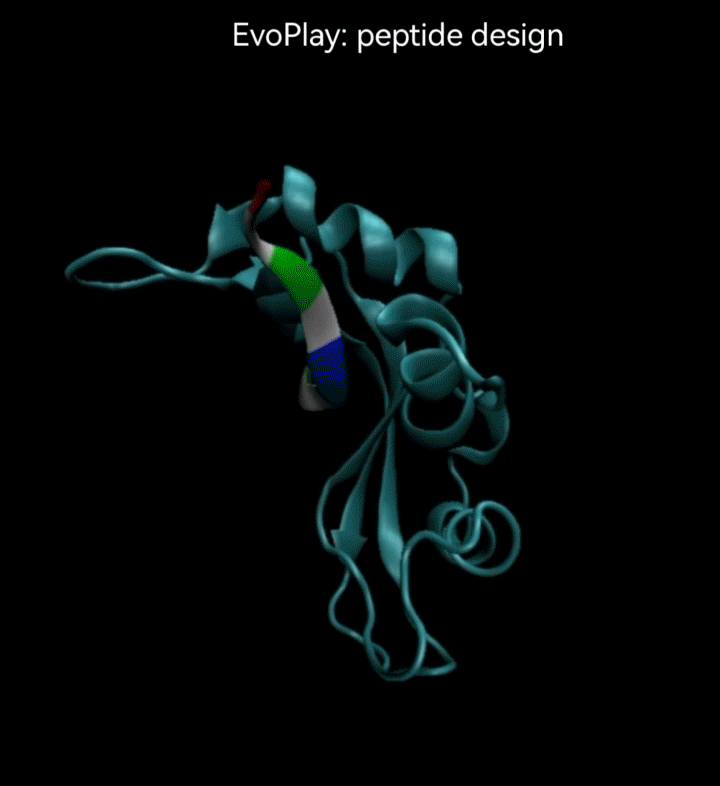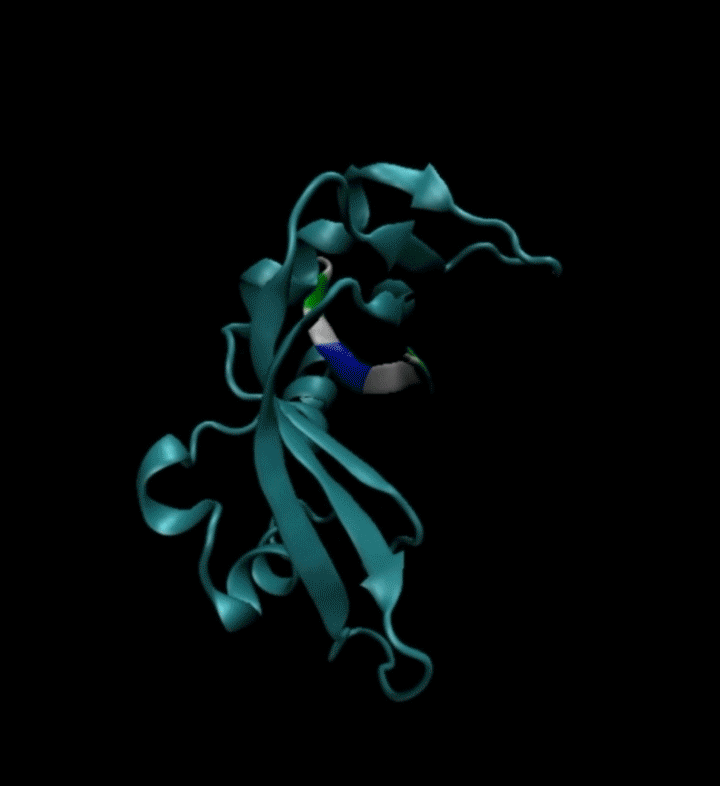
视频2. EvoPlay多肽设计任务展示。多肽设计任务的目的是通过策略性的改变多肽的氨基酸序列,以找到与受体蛋白质亲和力强的多肽。图中展示了EvoPlay在序列优化设计过程中,不同的多肽与受体蛋白在空间结合上的变化趋势。
在EvoPlay的多肽序列设计任务中,团队将AlphaFold2作为代理模型。AlphaFold2是DeepMind于2020年开发的深度学习模型,用于蛋白质结构预测,在CASP14的蛋白质结构预测实验中,它取得了显著的突破,大大提高了预测的准确性。它在蛋白质三维结构预测上的准确性已经达到实验室测量的精度,极大地增强了科研人员对蛋白质功能、相互作用及疾病机制的理解。这在药物设计、疾病治疗和合成生物学等领域都有着深远的影响。
在EvoPlay的多肽设计研究中,团队利用AlphaFold2构建了一个评估多肽与受体蛋白亲和力的评分器,为智能体提供奖励输出,从而优化多肽的设计策略。亲和力湿实验验证显示,在使用相同评分器作为代理模型时,结合蒙特卡洛树搜索(MCTS)和神经网络的EvoPlay在性能上显著超越其他基准方法,如贪心算法[25]和基于模拟退火的MCMC[26]。其设计的多肽与受体蛋白的亲和力达到了纳摩尔级别。值得注意的是,最近发布的ESMFold[2]在蛋白结构预测的精度上接近AlphaFold2。而且,由于其使用蛋白质语言模型ESM替代了多序列比对(Multiple Sequences Alignment),ESMFold的响应速度显著提高,使其有望替代AlphaFold2,成为EvoPlay结构相关任务的新代理模型。
EvoPlay实战1—荧光素酶设计
华大智造的研究成果中,其利用EvoPlay前瞻性地设计了36个荧光素酶突变体(其中的29个变体已申请专利[27]),并通过湿实验验证,结果显示,36个突变中有26个比野生型发出更强的生物荧光;其中,4个变体比野生型提高了6倍。另外,有11个突变体优于之前的所有变体,其中最好的突变体(GLuc-MT1)比华大之前内部突变库 (见专利[28])中表现最好的变体提高了2倍,或相当于比野生型提高7.8倍。此外,作者选取部分突变体进行MD模拟,进一步揭示了驱动催化活性的一些关键因素,这些分子动力学模拟结果进一步证明了EvoPlay的卓越性能以及其捕捉结构-功能映射中的某些内在规律的能力。总之,EvoPlay在寻找起始库之外更高适应性突变体方面非常有效,并且可以与现有的工程流程相集成。
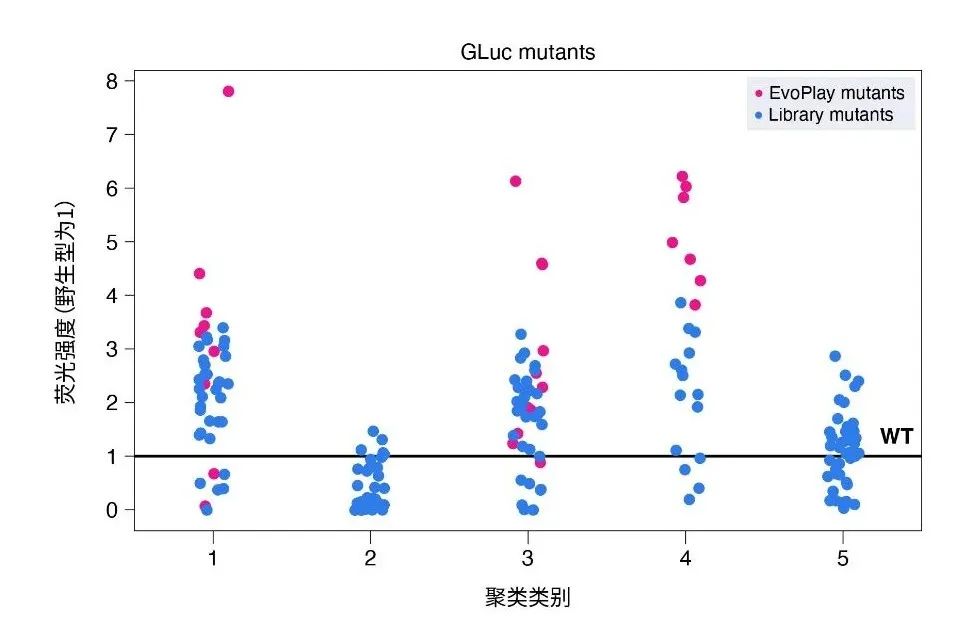
图3. 荧光素酶设计
EvoPlay实战2—多肽设计EvoPlay旨在高效地设计高质量多肽,适用于蛋白质-蛋白质相互作用、酶设计和药物发现等多种应用领域。另外,为了进一步验证了EvoPlay的设计多肽方面的性能,作者对于三种基准算法(EvoPlay, EvoBind[25],MCMC)的每个起始序列,从按训练损失排序的前五个设计序列中选择具有最高pLDDT(predicted local distance difference test )值的多肽,利用BLI(Bio-layer interferometry)技术检测多肽与蛋白的亲和力,实验结果显示EvoPlay设计的五条多肽都表现出针对RNase1蛋白的突出的亲和力,其中一条达到了最高的亲和力(Kd=80 nM),远高于野生型多肽的亲和力(Kd=1uM)。湿实验室验证结果表明EvoPlay优于EvoBind和MCMC的性能,并且表明EvoPlay能够有效地捕捉肽-蛋白质相互作用界面特征的能力,从而设计出高亲和力的多肽。
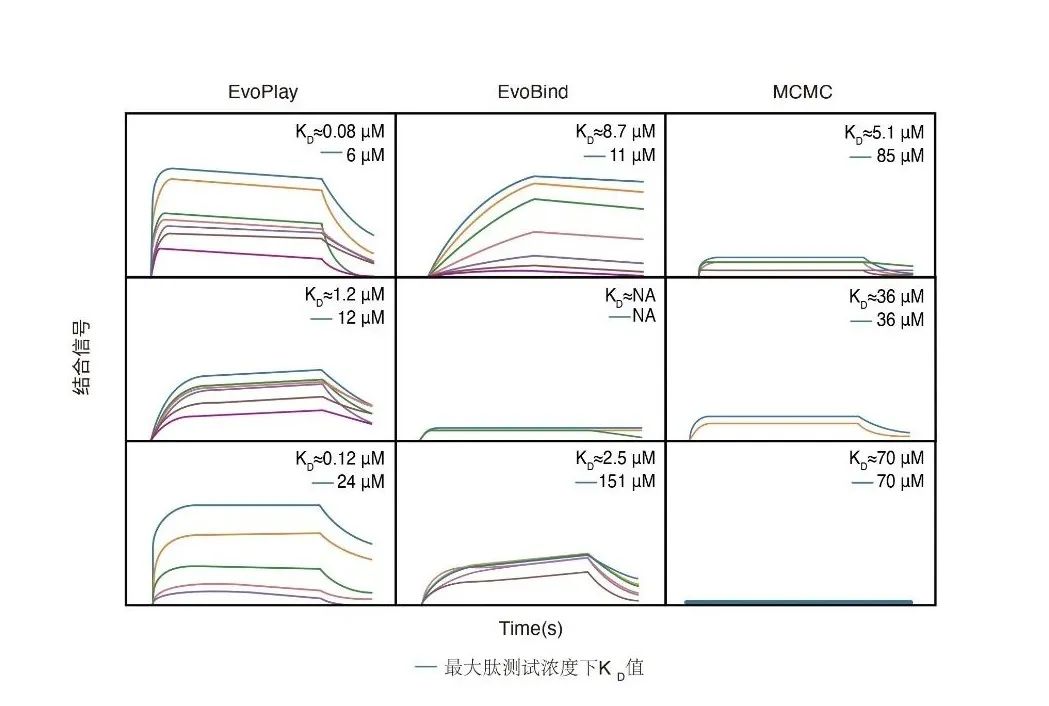
图4. 多肽设计
EvoPlay展望在EvoPlay投稿之后,David Baker团队在Nature上发表了标题为De novo design of luciferases using deep learning[29]一文,通过针对特定底物搜索得到合适的蛋白质骨架,并通过重新设计活性位点以及结合口袋来“从头设计”生成一个具有一定活性的全新蛋白,离彻底的“无中生有”设计蛋白又进了一步。此文章中的采样算法为MCMC,其特点是通过一定概率的“拒绝接受”采样来增加随机性以提高搜索广度。EvoPlay在多肽任务设计中的性能显著优于MCMC。
我们有理由相信在更多的理性机制分析以及更精密的结构代理模型的帮助下,EvoPlay的蒙特卡洛树搜索+神经网络可以更好地结合“从头设计”框架,从而为蛋白设计领域提供新的思路,也可以用来进一步优化测序仪里用到的各种工具酶。
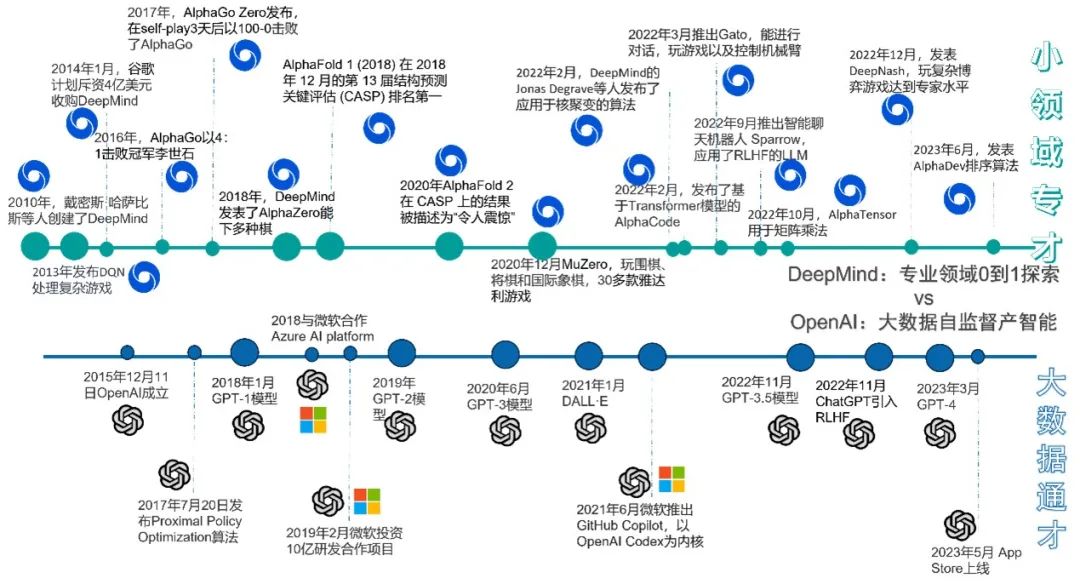
图5.DeepMind与OpenAI发展路线图对比
DeepMind作为强化学习的集大成者,从2013年玩雅达利游戏的深度Q网络(DQN)[5]到击败韩国围棋冠军的AlphaGo以及能玩多种棋类的AlphaZero,再到近些年在众多专业领域中从0到1的探索(同时玩棋类和视频游戏的MuZero[10],可以兼容对话加玩游戏再加控制机械臂等的Gato[11],用于矩阵乘法的AlphaTensor[12],精通复杂博弈游戏的DeepNash[13]以及今年的排序算法AlphaDev[14]等等),DeepMind无不在这些特殊领域把强化学习发挥到极致。与DeepMind的众多特殊领域专才模型策略形成鲜明对比的是OpenAI的通用大模型策略,即以大数据为依托,通过预训练大型的自然语言模型来获得通用人工智能的目的。OpenAI从2018年开始,一直致力于更新GPT模型,直到2022年11月,全面对齐RLHF(在与人的交流反馈中进行强化学习)的ChatGPT发布,标志着大语言模型(LLM)时代的正式来临, OpenAI的大数据通才模型战略进入新的阶段。但二者并非泾渭分明,把高效的向前搜索和向后回看用于大语言模型的 Prompt导航,很有可能赋予LLM长程规划和自主决策的能力,OpenAI和DeepMind的两条路线融合,将很有可能推动AGI照进现实。
随着自动化生物实验室的蓬勃发展,以及微流控技术广泛用于分子筛选和进化,更多的自动驾驶实验室(Self-driving Lab)即将出现。生命科学和技术实验室中的各个环节,包括实验的执行、数据的收集和分析、实验计划的制定等, 如Design-Build-Test-Learn (DBTL)的循环的自主执行,都可以由自动化系统和人工智能来完成,而不需要人类进行主动的干预或操作。智能体还可以通过LLM等工具整合外部知识,多轮迭代探索,连续学习,创造出满足人类需求的酶、抗体、小分子、基因序列甚至人造细胞。人工智能和机器人有巨大潜力推动人类科学进一步探索未知的边界,期待人工智能(AI)和生物智能(BI)和谐共生。
华大智造杨梦为文章通讯作者,王艺,唐辉,黄立超,潘璐璐,杨理想为文章的共同作者。该项目由科技部重点研发计划BT与IT融合重点专项、深圳市科技创新委员会重大专项支持。
参考文献
[1] Yang, K. K., Wu, Z. & Arnold, F. H. Machine-learning-guided directed evolution for protein engineering. Nat. Methods 16, 687-694 (2019).
[2] Lin Z, Akin H, Rao R, et al. Evolutionary-scale prediction of atomic-level protein structure with a language model[J]. Science, 2023, 379(6637): 1123-1130.
[3] Wang, J. et al. Scaffolding protein functional sites using deep learning. Science 377, 387-394 (2022).
[4] Dauparas, J. et al. Robust deep learning–based protein sequence design using ProteinMPNN. Science 378, 49-56 (2022).
[5] Mnih, V. et al. Human-level control through deep reinforcement learning. Nature 518, 529-533 (2015).[6]Silver, D. et al. Mastering the game of go without human knowledge. Nature 550, 354-359 (2017).
[7] Silver, D. et al. A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play. Science 362, 1140-1144 (2018).
[8] Feng, S., Sun, H., Yan, X. et al. Dense reinforcement learning for safety validation of autonomous vehicles. Nature 615, 620–627 (2023).
[9] Degrave, J. et al. Magnetic control of tokamak plasmas through deep reinforcement learning. Nature 602, 414-419 (2022).
[10] Schrittwieser J, Antonoglou I, Hubert T, et al. Mastering atari, go, chess and shogi by planning with a learned model[J]. Nature, 2020, 588(7839): 604-609.
[11] Reed S, Zolna K, Parisotto E, et al. A generalist agent[J]. arXiv preprint arXiv:2205.06175, 2022
[12] Fawzi A, Balog M, Huang A, et al. Discovering faster matrix multiplication algorithms with reinforcement learning[J]. Nature, 2022, 610(7930): 47-53.
[13] Perolat J, De Vylder B, Hennes D, et al. Mastering the game of Stratego with model-free multiagent reinforcement learning[J]. Science, 2022, 378(6623): 990-996.
[14] Mankowitz D J, Michi A, Zhernov A, et al. Faster sorting algorithms discovered using deep reinforcement learning[J]. Nature, 2023, 618(7964): 257-263.
[15] Schulman J, Wolski F, Dhariwal P, et al. Proximal policy optimization algorithms[J]. arXiv preprint arXiv:1707.06347, 2017.
[16] Rives, A. et al. Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences. Proc. Natl. Acad. Sci. 118, e2016239118 (2021).
[17] Meier, J. et al. Language models enable zero-shot prediction of the effects of mutations on protein function. Advances in Neural Information Processing Systems 34, 29287-29303 (NeurIPS, 2021).
[18] Hie, B. L. et al. Efficient evolution of human antibodies from general protein language models and sequence information alone. Nat. Biotechnol. (2023).
[19] Rao, R. et al. Evaluating protein transfer learning with TAPE. Advances in neural information processing systems 32 (NeurIPS, 2019).
[20] Sinai, S. et al. AdaLead: A simple and robust adaptive greedy search algorithm for sequence design. Preprint at https://arxiv.org/abs/2010.02141 (2020).
[21] González J, Dai Z, Hennig P, et al. Batch Bayesian optimization via local penalization. In Proc. 38th International Conference on Machine Learning 648-657 (PMLR, 2016).
[22] Angermueller, C. et al. Model-based reinforcement learning for biological sequence design. International conference on learning representations (ICLR, 2020).
[23] Haarnoja T, Zhou A, Abbeel P, et al. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor[C]//International conference on machine learning. PMLR, 2018: 1861-1870.
[24] Brookes, D., Park, H. & Listgarten, J. Conditioning by adaptive sampling for robust design. In Proc. 36th International Conference on Machine Learning 773-782 (PMLR, 2019).
[25] Bryant, P. & Elofsson, A. EvoBind: in silico directed evolution of peptide binders with AlphaFold. bioRxiv (2022).
[26] Anishchenko, I. et al. De novo protein design by deep network hallucination. Nature 600, 547-552 (2021).
[27] Yang, M., Pan, L. L., Liu, W. J., Wang, Y., et al. 新型桡足类荧光素酶突变体及其应用. PCT/CN2023/087445 (2023).
[28] Zhang, W., Dong, Y. L., Li, J., Zheng, Y. & Zhang, W. W. A Novel Gaussian Luciferase and Application. PCT/CN2021/144051 (2021).
[29] Yeh A H W, Norn C, Kipnis Y, et al. De novo design of luciferases using deep learning[J]. Nature, 2023, 614(7949): 774-780.











